"I am a bit skeptical about statistics. According to statistics, a millionaire and a poor guy each have half a million." ~ Franklin Roosevelt.
Statistics
German
R
Python
Mean
Median
Modal
Quartil
Box-Plot
Author
Fazliddin Sultonov
Published
May 28, 2024
Bei der deskriptiven Statistik werden die Daten zusammenfassend dargestellt und beschrieben, so dass mann den Wald statt viele Bäume sieht (Sauer 2019). Die Daten werden also explorativ untersucht, um den ersten Eindruck von ihnen zu bekommen. Dies würde man im Bereich Machine Learning als Feature Engineering bezeichnen (Alby 2022). Die deskriptive Statistik wird auch als beschreibende Statistik oder deskriptive Datenanalyse bezeichnet und hat das Ziel einen Überblick über die Verteilung der Daten anhand Kennzahlen, Tabellen und Grafik zu verschaffen.
Lagemaße (engl. Estimates of Location), auch Maße der zentralen Tendenz genannt, gibt Auskunft darüber, wo die Mitte der Verteilung liegt. Anders gesagt, man reduziert mehrere Werte auf einen Wert (Kennzahl), der alle Werte repräsentiert (viele einzelne Bäume -> Wald). Mittelwert, Median und Modalwert gehört dazu.
flowchart LR
A("Estimates of Location\n(Lagemaße)")
B[["- Mean\n- Median\n- Modus\n- Quantil"]]
A --> B
style A text-align:center;
Lagemaße
flowchart LR
A("Estimates of Variability\n(Streuungsmaße)")
B[["- Standard deviation (Standardabweichung)\n- Variance (Varianz)\n- Range (Spannweite)\n- Interquartile range, IQR (Interquartilsabstand)"]]
A:::myClass --> B
classDef myClass style: text-align:center
Streuungsmaße
Mean
Das arithmetisches Mittel (engl. mean) häufig als Mittelwert bezeichnet, wird am häufigsten benutzt. Mittelwert wird berechnet, indem man alle Werte addiert \((x_1, x_2, ..., x_n)\) und die Summe durch die Anzahl der Werte (n) dividiert: \[
\bar{x} = \frac{x_1+x_2+x_3+...+x_n}{n} = \frac{1}{n}\sum_{i = 1}^{n}{x_i}
\] Man möge sich vorstellen, man würde eine Straßenumfrage machen und die Menschen nach ihrem Beruf, Alter und Einkommen fragen.
Um den Mittelwert zu berechnen gibt es in R und Python die Funktion mean(). Zu beachten bei der Berechnung von mean ist, dass der Mittelwert metrische Daten voraussetzt. Mean vom Einkommen und Alter ist wie folgt berechnet:
m_age <-mean(df$age); m_inc <-mean(df$income)glue::glue("mean of age: {m_age}\nmean of income: {round(m_inc, 2)}")#> mean of age: 51#> mean of income: 2027.78
age_m = r.df.age.mean(); inc_m = r.df["income"].mean()print(f"mean of age: {age_m}\nmean of income: {round(inc_m, 2)}")#> mean of age: 51.0#> mean of income: 2027.78
Interpretation
Von neun Befragten ist das arithmetisches Mittel fürs Alter: 51 und fürs Einkommen: 2.161. Also, man kann sagen, die Befragten sind im Durchschnit 51 Jahre alt und verdienen durchschnitlich 2.027,78 (in Euro, Dollar, in was auch immer) im Monat.
Median
Median ist der Wert, der in der Mitte von den der Größe nach sortierten/geordneten Werten ist. Er halbiert die Verteilung und gibt an, dass eine Hälfte der Verteilung von ihm kleiner und andere Hälfte größer ist.
Um Miedian zu berechnen gibt es in R und Python die Funktion median(). Zu beachten ist, dass der Median metrische und ordinale Daten voraussetzt. Median vom Einkommen und von der Größe ist wie folgt berechnet:
med_tall <-median(df$tall); med_inc <-median(df$income)glue::glue("median of tall: {med_tall}\nmedian of income: {med_inc}")#> median of tall: 1.73#> median of income: 2050
import pandas as pdtall_med = r.df.tall.median(); inc_med = r.df["income"].median()print(f"median of tall: {tall_med}\nmean of income: {inc_med}")#> median of tall: 1.73#> mean of income: 2050.0
Interpretation
Von neun Befragten ist der Median für die Größe: 1.73 und fürs Einkommen: 2.050. Also, man kann sagen, die Hälfte (50%) der neuen Befragten sind kleiner als 1.73 Meter und verdienen unter 2.050 (in Euro, Dollar, in was auch immer) im Monat. Oder andersrum, die Hälfte (50%) der Befragten sind größer als 1.73 Meter und verdienen über 2.050 im Monat.
Modus
Modalwert, auch Modus genannt, ist der Wert, der am häufgsten vorkommt. Der Modus kann für metrische, ordinale und nominale Daten berechnet werden. Für nominale Daten ist der Modus der einzige Kennwert, um mittleren Wert zu bestimmen. In R gibt es keine Funktion für Modus, man kann durch die Funktion table den Modalwert anzeigen lassen.
show the code
cat("Frequence table for variable profession:")table(df$profession) # Häufigkeitstablle# Modus-Maximaler Wert von der Freq.Tablecat("Mode for variable profession - Max value of FreqTable: ", max(table(df$profession)))cat("\n\nFrequence table for variable tall:")table(df$tall) # Häufigkeitstabllecat("Mode for variable tall - Max value of FreqTable: ", max(table(df$tall)))
#> Frequence table for variable profession:
#> Doctor Pensioner Professor Student Teacher
#> 2 3 1 2 1
#> Mode for variable profession - Max value of FreqTable: 3
#>
#> Frequence table for variable tall:
#> 1.68 1.7 1.72 1.73 1.75 1.77 1.78
#> 1 1 1 2 2 1 1
#> Mode for variable tall - Max value of FreqTable: 2
show the code
#from statistics import mode# tall_med = r.df.tall.median(); inc_med = r.df["income"].median()# print(f"median of tall: {tall_med}\nmean of income: {inc_med}")freq_prof = r.df["profession"].value_counts() # FreqTable for var professionmodi_prof = r.df["profession"].value_counts().max() # Modi for var professionfreq_tall = r.df["tall"].value_counts() # FreqTable for var tallmodi_tall = r.df["tall"].value_counts().max() # Modi for var tallprint("Frequence table for variable profession:")print(freq_prof)print(f">> Mode for variable profession - Max value of FreqTable: {modi_prof}")print("\nFrequence table for variable tall:")print(freq_tall)print(f">> Mode for variable tall - Max value of FreqTable: {modi_tall}\n")
#> Frequence table for variable profession:
#> profession
#> Pensioner 3
#> Doctor 2
#> Student 2
#> Teacher 1
#> Professor 1
#> Name: count, dtype: int64
#> >> Mode for variable profession - Max value of FreqTable: 3
#>
#> Frequence table for variable tall:
#> tall
#> 1.75 2
#> 1.73 2
#> 1.72 1
#> 1.68 1
#> 1.70 1
#> 1.78 1
#> 1.77 1
#> Name: count, dtype: int64
#> >> Mode for variable tall - Max value of FreqTable: 2
Interpretation
Für Modus gibt es nicht besonders viel zu interpretieren. Man könnte sagen, unter Befragten sind am meisten die Rentner oder die meisten haben die Größe 1.73 Meter.
Outliers: Mean vs Median
Es gibt viele Fälle, wo der Median gegenüber Mean ein besseres Lagemaß darstellt, z.B. wenn es in dem Datensatz extreme Werte (Außreißer, engl. outlier) gibt. Bei Extremfällen wird der Median nicht von Ausreißern beeinflusst, die das Ergebnis verfälschen können. Wir erweitern das Beispiel von Umfrage, indem wir einen Ausreißer hinzufügen. Also, wir hätten noch einen Tiktoker oder Blogger befragt, der jung, groß ist und mehr als die anderen Befragten verdient. Da wird unser ursprünglicher Mittelwert ändern und höher ausfallen.
show the code
v <-data.frame("Bloger", 19, 1.84, 5600); names(v) <-names(df)extrem <-rbind(df,v)cat("New df with outlier:\n")tail(extrem, n =3)# Meanscat("\nWithout outlier:\n")glue::glue("income: mean - {round(mean(df$income),2)}, median - {median(df$income)}\nage: mean - {mean(df$age)}, median - {median(df$age)}")#glue::glue("Median income: {median(df$income)}\nMedian age: {median(df$age)}")cat("\nWith outlier:\n")glue::glue("income: mean - {mean(extrem$income)}, median - {median(extrem$income)}\nage:mean - {mean(extrem$age)}, median - {median(extrem$age)}")#glue::glue("Median income: {median(extrem$income)}\nMedian age: {median(extrem$age)}")
#> New df with outlier:
#> profession age tall income
#> 8 Student 25 1.77 950
#> 9 Pensioner 82 1.73 1100
#> 10 Bloger 19 1.84 5600
#>
#> Without outlier:
#> income: mean - 2027.78, median - 2050
#> age: mean - 51, median - 51
#>
#> With outlier:
#> income: mean - 2385, median - 2125
#> age:mean - 47.8, median - 49
Wie man oben sieht, durch Ausreißer, hat sich Mittelwert für Einkommen von 2.027,78 auf 2.385 gestiegen und alter von 51 auf 47.8 gesunken. Bei Median hat sich nicht so groß geändert, nämlich von 2.050 auf 2.125 gestiegen und für die Variable alter von 51 auf 49 gesunken.
Usage
Der mittlere Wert, wie wir gesehen haben auf unterschiedliche Weise ermittelt. Daher ist es sinnvoll, dass man sich überlegt, anhand den Gegebenheiten (wie z.B. Skalenneveau der Daten) welches Lagemaß am besten geeignet ist. Hier ist meine kurze Zusammenfassung:
Bei nominalen verwendet man den Modus, da andere Lagemaße dafür nicht geeignet sind.
Anwenung von Median ist dann sinnvoll, wenn
die Daten ordinal sind.
man weiß, dass man Außreßer hat.
Hat man quantitative Daten und symmetrische Verteilung vorligt, dann ist arithmetisches Mittel am besten geeignet.
Quantile & Quartile
Im Gegensaz zu Median, der die Daten in zwei gleiche Größe aufteilt, wird beim Quantil die sortierten Daten in unterschiedlich große Abschnitte, nämlich in \(x_p\)- Quantile oder x% (px100%)- Quantile aufgeteilt. Diese aufgeteilte abschnitte wären dann Quantile. Zum Beispiel 10%-Quantil oder 0,1-Quantil sagt aus, dass 10% der Daten in der verteilung liegt unter diesem Quantil, und der Rest (1-p, also 90%) liegt darüber. Teilt man die Daten in vier gleich große Teile, spricht man von speziellen Quantilen, nämlich von Quartilen.
0,25/25%-Quantil = untere/erste Qauartil = Q1 - besagt, dass mindestens 25% der n-Daten kleiner oder gleich \(x_{0,25}\) sind.
0,50/50%-Quantil = mittlere/zweite Qauartil = Q2 - gleich Median, mindestens 50% der n-Daten kleiner oder gleich \(x_{0,50}\) sind.
0,75/75%-Quantil = obere/dritte Qauartil = Q3 - besagt, dass mindestens 75% der n-Daten kleiner oder gleich \(x_{0,75}\) sind.
Bei p = 0.1, 0.2, … spricht man von Dezilen, bei 0.01, 0.02, … von Perzentilen.
Als Beispiel, stellen wir wieder vor, wir machen eine kleine Umfrage und fragen wir 10 Leute danach, wie lange sie am Tag ihre Zeit mit Handy verbringen. Sagen wir, die Antwort wie folgt (die Zahlen sind ausgedacht):
Um die Quartile zu berechnen muss man zu erst die Anzahl der Datenmenge (n) mit p (0.25, 0.50, 0.75) multiplizieren \(n*p\). Je nachdem, ob das Ergebis ganzzahlig oder nicht ganzzahlig ist, muss man für die weitere Berechnung diese Formel benutzen: \[x_p = \begin{cases}
\frac{1}{n}(x_{(np)} + x_{(np+1)}) & if (p\cdot n) &\text{wholenumbered}\\
x_{(|np|+1)} & if (p\cdot n)&\text{not wholenumbered}\end{cases}\] Hier ist nochmal die visuelle Darstellung zur Berechnung von Quartilen
Quartile (25%, 50%, 75%)
Zum Glück muss man das ganze nicht händisch ausrechnen. Dafür gibt es in R die Funktion quantile(). Außerdem gibt die Funktion summary()(wie describe() in Python) den ersten Eindruck über den Daten mit den Lagemaßen wie Mean, Median, Q1, Q2 = Median, Q3, Min und Max.
show the code
cat("Vector time: Qauartile: 25%-, 50%-, 75%- Quantile\n")quantile(time) # Qauartile: 25%-, 50%-, 75%- Quantilecat("\nVector time: 0,6- Quantil:\n")quantile(time, 0.60) # 60%- Quantilcat("\nVector time: Summary\n")summary(time) # Summary for variable incomecat("\nDescriptive measures with summary() for df:\n")summary(df)# summary(df$age) # Summary for selected variable (age)
#> Vector time: Qauartile: 25%-, 50%-, 75%- Quantile
#> 0% 25% 50% 75% 100%
#> 1.000 1.775 2.400 3.150 4.000
#>
#> Vector time: 0,6- Quantil:
#> 60%
#> 2.7
#>
#> Vector time: Summary
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> 1.000 1.775 2.400 2.460 3.150 4.000
#>
#> Descriptive measures with summary() for df:
#> profession age tall income
#> Length:9 Min. :21 Min. :1.680 Min. : 950
#> Class :character 1st Qu.:39 1st Qu.:1.720 1st Qu.:1100
#> Mode :character Median :51 Median :1.730 Median :2050
#> Mean :51 Mean :1.734 Mean :2028
#> 3rd Qu.:68 3rd Qu.:1.750 3rd Qu.:2600
#> Max. :82 Max. :1.780 Max. :3500
In Python gibt es auch die Funktion quantile(), man muss in Klammern die gewünschte(n) Quantil(e) in Listenformat eingeben. Die Funktion ist in Pandas oder NumPy.
show the code
print("Quartile for one variable (age):")r.df["age"].quantile([0.25,0.5,0.75])print("\nQuantile for more variables:")r.df[["age", "income", "tall"]].quantile([.1, .25, .5, .75], axis =0)# with describe()print("\nDescriptive measures with discribe() for df:")# r.df[["age", "tall"]].describe() # for selected variablesr.df.describe()
#> Quartile for one variable (age):
#> 0.25 39.0
#> 0.50 51.0
#> 0.75 68.0
#> Name: age, dtype: float64
#>
#> Quantile for more variables:
#> age income tall
#> 0.10 24.2 1030.0 1.696
#> 0.25 39.0 1100.0 1.720
#> 0.50 51.0 2050.0 1.730
#> 0.75 68.0 2600.0 1.750
#>
#> Descriptive measures with discribe() for df:
#> age tall income
#> count 9.000000 9.000000 9.000000
#> mean 51.000000 1.734444 2027.777778
#> std 20.621591 0.032059 986.189355
#> min 21.000000 1.680000 950.000000
#> 25% 39.000000 1.720000 1100.000000
#> 50% 51.000000 1.730000 2050.000000
#> 75% 68.000000 1.750000 2600.000000
#> max 82.000000 1.780000 3500.000000
Interpretation
Quantile oder Quartile gibt einen der ersten Überblick von der Datenverteilung. Dadurch kann man die Aussage treffen, dass eine bestimme Teil der gesamten Verteulung liegt unter oder über ein Quantil/Quartil. Nehmen wir das Beispiel von oben mit dem Handy.
# How many time spent you for handy in a day?handy <-c(2.3, 1.7, 3, 2, 2.5, 3.2, 3.4, 1.5, 4, 1)# Quartilequantile(handy)#> 0% 25% 50% 75% 100% #> 1.000 1.775 2.400 3.150 4.000# 0.6 Quantilquantile(handy, 0.6)#> 60% #> 2.7
Daraus kann man ablesen, dass drei Viertel (75%) der 10 Befragten verbringen ihre Zeit bis über 3 Stunden mit dem Handy, oder zweite Zahl, 60% der Befragten verschwinden bis 2.7 Stunden am Tag ihrer Zeit mit dem Handy.
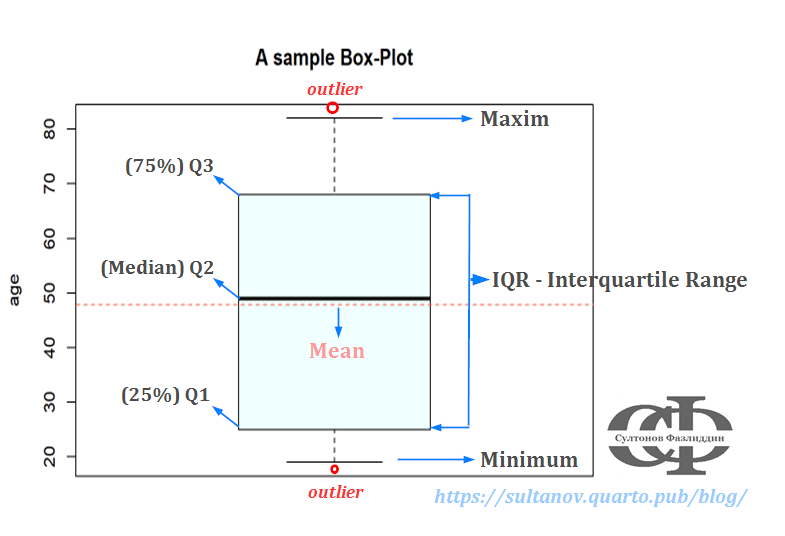
Box-Plot
Bei der deskriptiven Analyse greift man oft zu graphischen Methoden, vor allem, wenn man eien ngroßen Datensatz hat, um ersten Eindruck über das Verhalten der Daten zu gewinnen. Box-Plot kommt am häufgsten zur Anwendung. Er setzt hauptsächlich 5 Kennzahlen (\(x_{min}\), \(x_{0,25}\), \(x_{0,50}\), \(x_{0,75}\), \(x_{max}\)) zusammen und stellt sie graphisch dar, zeigt auch Außreißer. Hier noch eine visuelle Darstellung:
Box-Plot
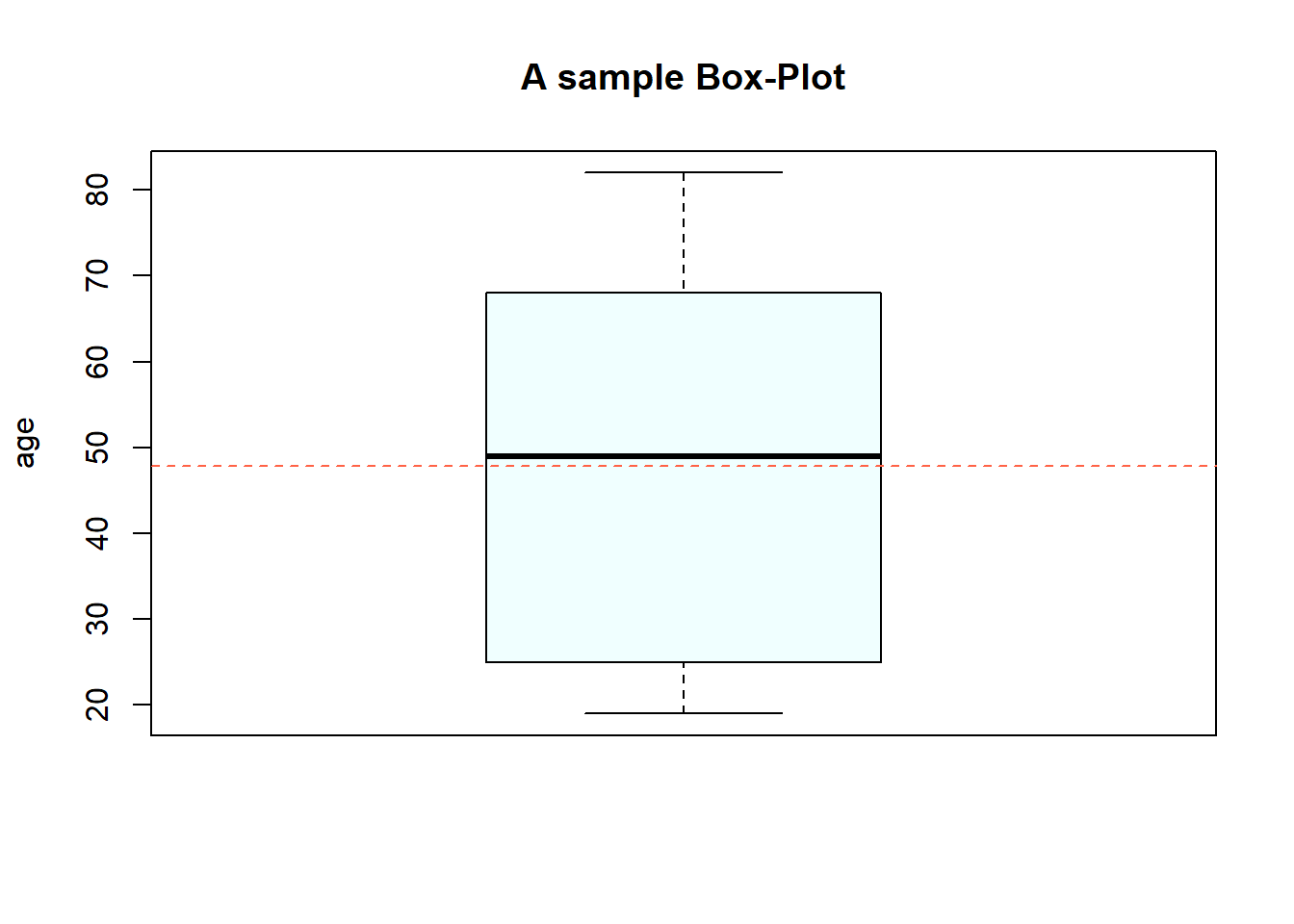
In R gibt es Basefunktion boxplot() für Box-Plot. Außerdem kann man auch durch ggplot-Package erstellen. In Python auch diese Funktion in den Modeulen matplotlib oder seaborn.
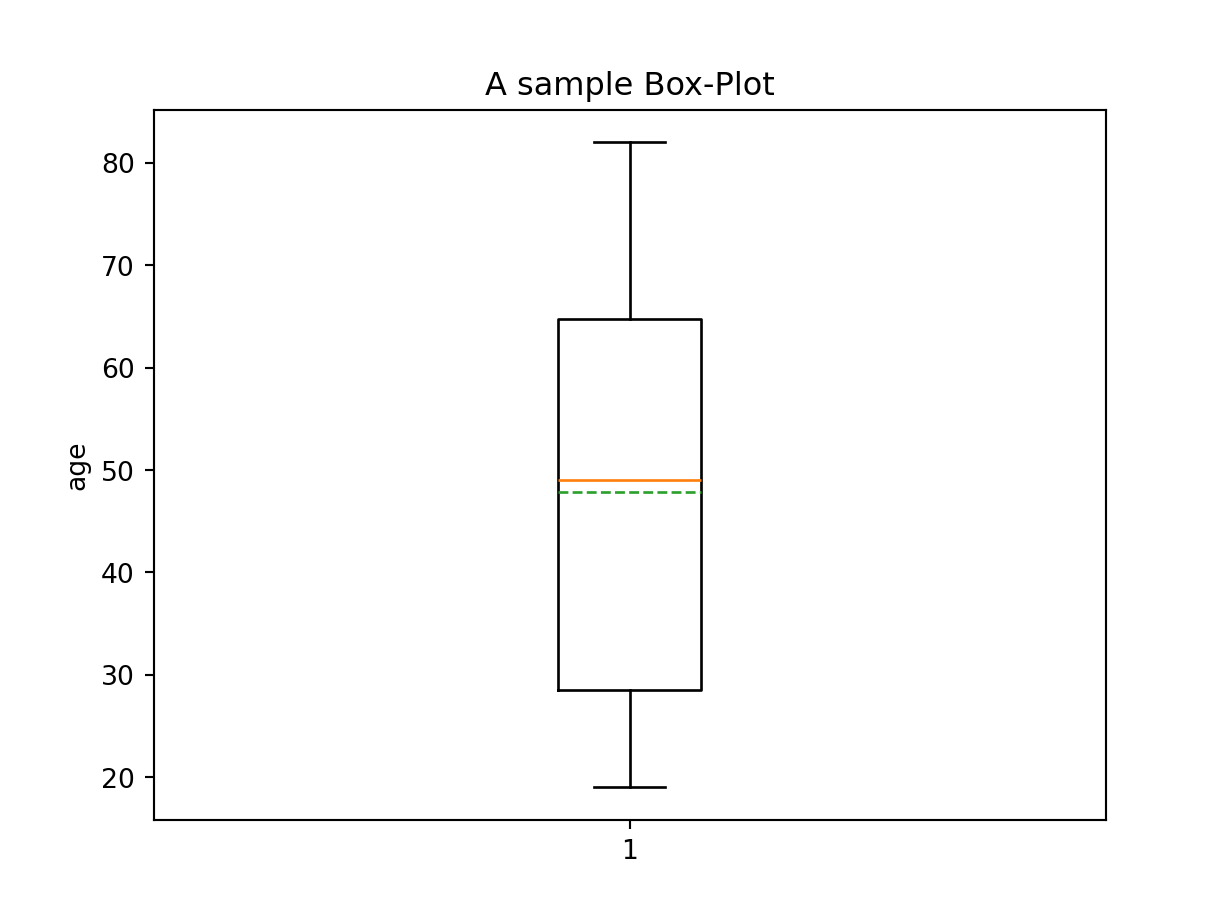
import matplotlib.pyplot as plt# Create a boxplot for the desired columnplt.boxplot(r.extrem["age"], showmeans =True, meanline =True, showfliers =False)# Add labels and titleplt.xlabel("")plt.ylabel("age")plt.title("A sample Box-Plot")# Show the plotplt.show()
#> {'whiskers': [<matplotlib.lines.Line2D object at 0x000001C5612BEBA0>, <matplotlib.lines.Line2D object at 0x000001C5612BEE40>], 'caps': [<matplotlib.lines.Line2D object at 0x000001C5612BF140>, <matplotlib.lines.Line2D object at 0x000001C5612BF440>], 'boxes': [<matplotlib.lines.Line2D object at 0x000001C5612BE2A0>], 'medians': [<matplotlib.lines.Line2D object at 0x000001C5612BF740>], 'fliers': [], 'means': [<matplotlib.lines.Line2D object at 0x000001C5612BFA10>]}
Boxplot von oben ist für die Variable age (Alter) von der Befragten in dem Beispieldataframe erstellt. Wie man im Plot sieht, sind die Hälfte (50%) der Daten liegen in dam Box (IQR), 25% oberhalb und 25% unterhalb des Boxes (gestrichene Linien ausßerhalb des Boxes im Plot). Man kann es so interpretieren: 50% der Befragten/personen sind zwischen 25 und 68 Jahre alt. Durchgezogene Linie in der Mitte ist Median = 51, und die gestrichene Linie ist Mittelwert = ca.49 (kann man zu Plot hinzufügen, ist nicht Bestandteil von Box-Plot), also kann man daraus eine Schlussfolgerung ziehen, dass durchnittliches Alter von befragten Personen um die 50 Jahre ist. 25% der Personen sind unter 25 Jahren, 25% über 68 Jahre und 50%, wie gesagt, zwischen 25-68 Jahre alt.
Alby, Tom. 2022. Data Science in Der Praxis : Eine Verständliche Einführung in Alle Wichtigen Verfahren. Rheinwerk Verlag GmbH,.
Dr. Sandro Scheid, Prof. Dr. Stefanie. 2021. Data Science - Grundlagen, Methoden Und Modelle Der Statistik. Carl Hanser Verlag München.
große Schlarmann, Jörg. 2024. Statistik mit R und RStudio - Ein Nachschlagewerk für Gesundheitsberufe. Krefeld: Hochschule Niederrhein. https://www.produnis.de/R.
Kronthaler, Franz. 2021. Statistik angewandt mit dem R Commander. 2nd ed. Springer-Verlag GmbH Deutschland.
Peter Bruce, Peter Gedeck, Andrew Bruce. 2020. Practical Statistics for Data Scientists. 2nd ed. O’Reilly Media, Inc.,.
Sauer, Sebastian. 2019. Moderne Datenanalyse mit R. Springer Gabler.
Team, DATAtab. 2022. “Tutorials: Erste Schritte Mit DATAtab.”https://datatab.net/.